How we audited Beauty Clinic A: behind a Pro Competitive Intelligence audit
ANYÉ's first published case study — three-layer pipeline applied to a Jakarta beauty clinic. v4 release: 9 chapters, 5 ANYÉ Lenses, 13-play IPM. Live workpaper xlsx + 30+ page PDF.
Outcomes
The question that starts every ANYÉ audit is one sentence. Clinic owners say it with different words — sometimes frustrated, sometimes calm, sometimes pointing at a P&L — but the sentence is the same: “I’m spending Rp 50M a month on marketing. The next Rp 100M — where should it actually flow?”
Easy question to ask. Hard question to answer in a way you can defend three months later.
Most Indonesian marketing agencies answer with intuition. More Instagram posts. Boost the good story. More Reels. More ads. Every recommendation sounds reasonable in the room and stops being defensible by quarter-end. When the client asks “why did we choose this direction?”, the answer is opinion. Opinions don’t compound; they depreciate.
ANYÉ built the engine as the answer to that frustration. This article walks the engine through one case — Beauty Clinic A, a Jakarta beauty clinic — so you can see what happens when every rupiah has evidence attached.
What we audited
Beauty Clinic A is one of about 50–65 beauty clinics in Jakarta with revenue in the Rp 200–800M/month band and minimal in-house marketing. That’s ANYÉ’s sweet spot — businesses big enough to have a marketing budget, small enough to feel every misallocated rupiah.
Our competitive audit isn’t only an examination of what Beauty Clinic A does. It’s also an examination of the three peers most relevant to its pricing power: ZAP Clinic (Cost Leader, Scale Operator), JAC (Differentiation-Focus, Niche Specialist), and Erha (Cost Leader, Scale Operator). That’s the context. Beauty Clinic A isn’t measured against “the industry” — abstract — but against three real competitors it’s losing or winning against every day.
Layer 1 — evidence collection across eight parallel surfaces
The ANYÉ engine is a three-layer pipeline. The first layer collects evidence.
Modern marketing has eight competitive surfaces — Google search, Google Maps, TikTok, Instagram, marketplaces like Tokopedia and Shopee, ad libraries, plus one vertical-specific source (for clinics: insurance panels, accreditations, BPJS). Each surface has its own language, data format, and scraping behavior.
Most agencies pick one or two of the eight and call it a “competitive audit.” ANYÉ runs eight in parallel.
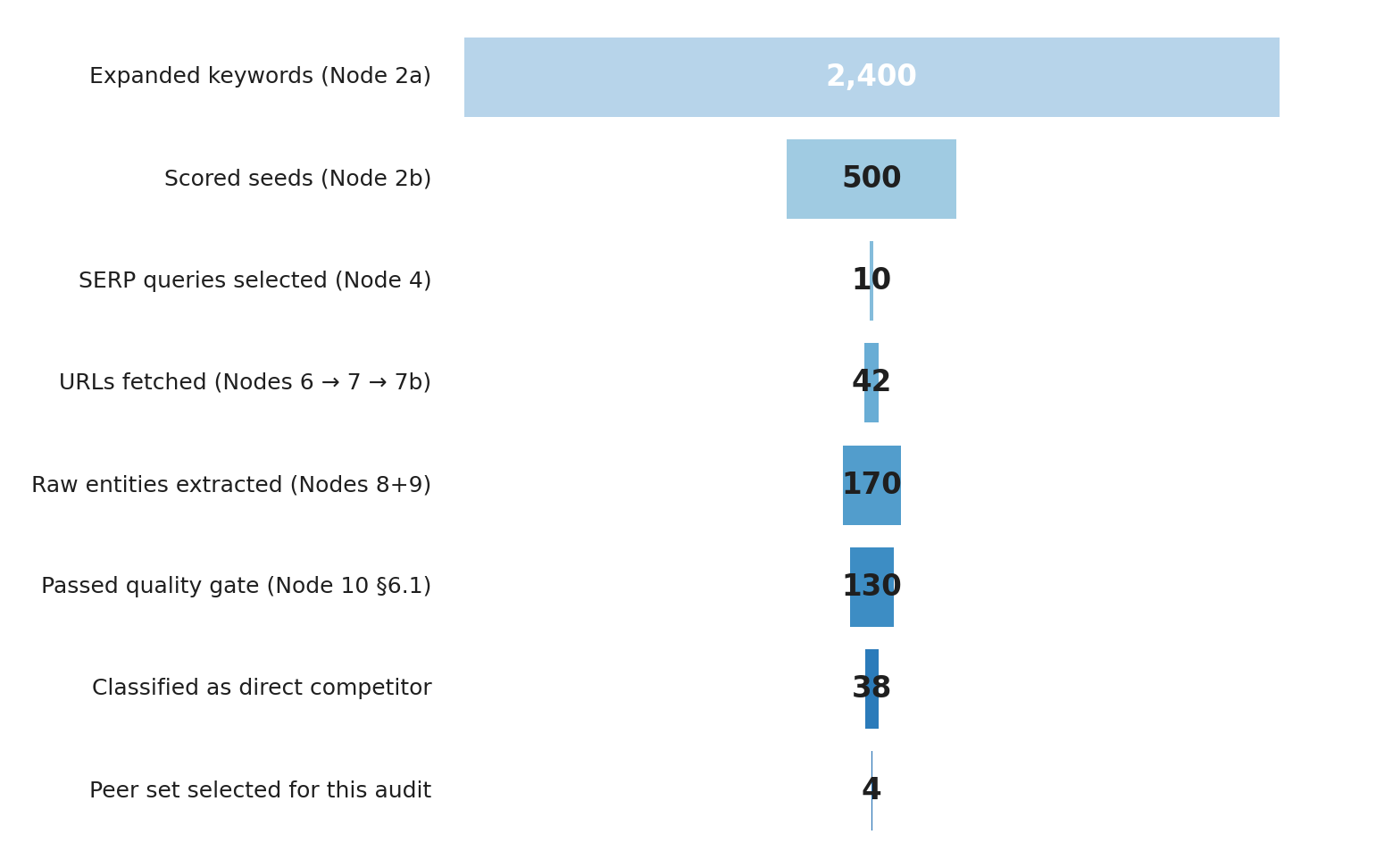 Exhibit 1 — competitive evidence pipeline funnel: from 2,400 keywords expanded down to 4 selected peers for this audit. Caps at each node documented in search-volume cap, fetch cap, and quality threshold.
Exhibit 1 — competitive evidence pipeline funnel: from 2,400 keywords expanded down to 4 selected peers for this audit. Caps at each node documented in search-volume cap, fetch cap, and quality threshold.
For Beauty Clinic A, that funnel produced a 61-data-point dataset under the Process Map (4 of the 61 are GAPs — see methodology note below). Distribution: 4 in Group A (Product Identity), 8 in Group B (Customer Voice), 4 in C (Market Demand), 4 in D (Competitive Position), 5 in E (Entity Reputation), 5 in F (Digital Infrastructure), 10 in G (Conversion Capability), 14 in H (Visibility), 5 in I (Comparison Capability), 3 in J (Content Intelligence). Every data point has a numeric value traceable to an auditable source.
Total cost of one Layer 1 cycle: ~$0.23. That’s not a typo. The economics that make Pro CI Subscription high-margin are the economics that let ANYÉ price at Rp 12M while still being an absurd value proposition for the client.
This part is still semi-manual today. Most of Group B (Customer Voice) and Group J (Content Intelligence) still run via Claude prompt templates rather than automated competitive evidence pipelines. We publish both publicly because what’s manual today will be automated six weeks from now — that’s the build-cycle commitment.
Layer 2 — turning evidence into defensible scores
The 61-data-point dataset feeds into the rating engine, five deterministic functions that compute — not judge — Beauty Clinic A’s competitive position.
The first output: a Porter Stuck-in-Middle classification with confidence 0.30. Not a flattering label. It’s the mathematical consequence of a data-point combination that can’t be ignored:
- F1 (GBP exists + claimed) = 100
- F7 (Website link present on GBP) = 100
- F8 (WhatsApp enabled on GBP) = 100
- F14 (Website loads) = 100
- F20 (IG account active + verified) = 100
- E20 (IG verification) = 100
— Beauty Clinic A’s basic digital infrastructure is excellent. But:
- G15 (Price ranges visible on website) = 0
- G16 (Specific treatment pricing) = 0
- I1 (Why-us / differentiation page) = 0
- I2 (Comparison-stage blog content) = 0
- E19 (Before/after gallery exists) = 0
— no public differentiation signals. Operational excellence + zero public differentiation = Stuck-in-Middle. The engine doesn’t invent this classification. It computes it from the ten specific data points above.
Anyone running the rating engine on the same dataset gets the same classification.
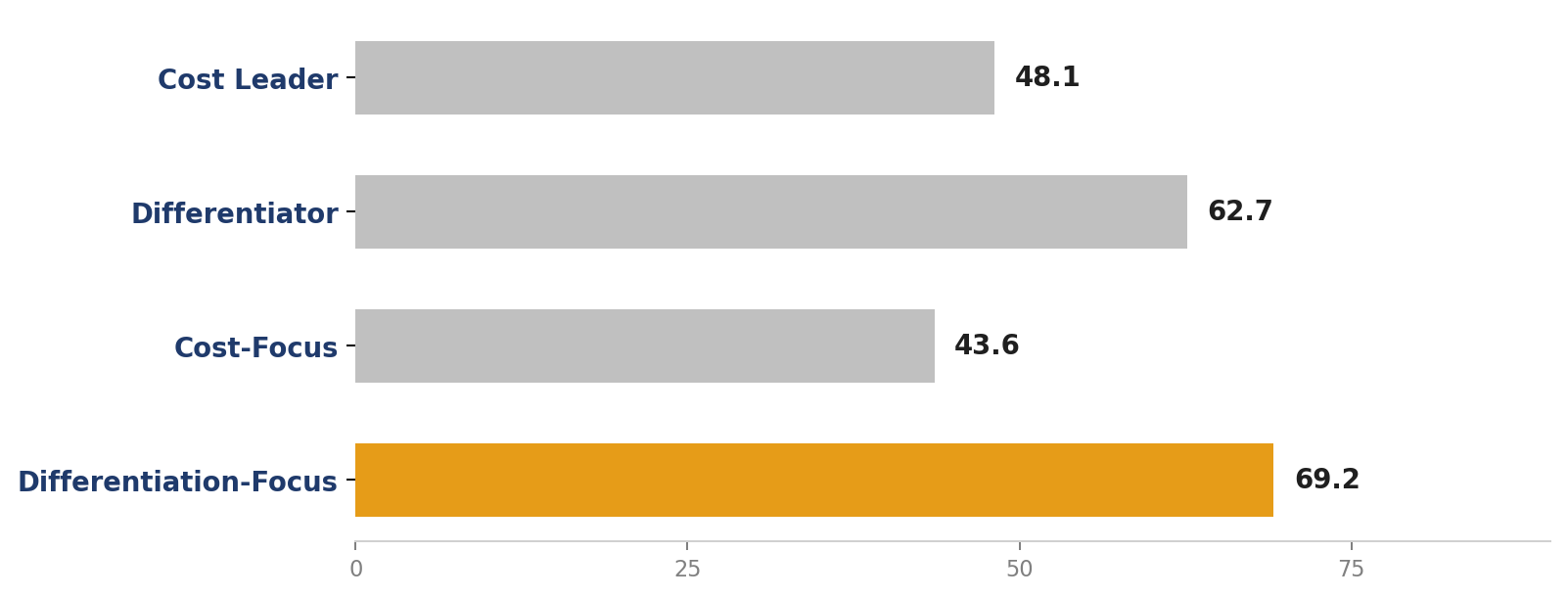 Exhibit 2 — Beauty Clinic A’s four Porter scores. Margin between top classification (Differentiation-Focus 69.2) and second (Differentiator 62.7) is only 6.5 points — below the 10-point threshold separating decisive archetypes from Stuck-in-Middle.
Exhibit 2 — Beauty Clinic A’s four Porter scores. Margin between top classification (Differentiation-Focus 69.2) and second (Differentiator 62.7) is only 6.5 points — below the 10-point threshold separating decisive archetypes from Stuck-in-Middle.
Second lens — Maister Trust, decomposed honestly
Trust is a multiplicative quantity, not additive. One weak component drags the whole score down even when three other components are strong. The Maister equation — Trust = (Credibility × Reliability × Intimacy) / Self-Orientation — captures this mathematically.
For Beauty Clinic A (engine v2 re-run 2026-04-27): C=48, R=100, I=48, S=78 → Trust 44.5 (band B).
Reliability 100 is the strongest pillar on the surface. Methodology note: of the four R inputs (G2 WA response time tested, G4 phone answered, E21 review velocity trend, F14 website uptime), two are GAPs — G2 and G4 await a manual phone test scheduled for the audit follow-up. The R=100 value is partially an artifact of sparse inputs: the engine averages whatever inputs are present, and the two measured inputs (E21 + F14) are both high. After G2 + G4 are filled via manual test, R is expected to drop to the 65-75 range. The clinic still functions well at the operational basics — that’s why the Retention score is good (we’ll get there).
Intimacy 48 is the weakest pillar. Digital touchpoints feel institutional, not personal. The website bio talks about the clinic, not the patient. WhatsApp messages are templated, not adapted. There’s no structured Week-12 follow-up.
Self-Orientation 78 is the number to watch. High Self-Orientation = low trust. Website copy leans toward “we” instead of “you” (B3 negative themes 35 → inverted 65; I9 pricing-clarity 10 → inverted 90 → S avg 78). That’s the slow leak Maister warned about most.
The Maister 60-point threshold is where price pressure stops. Beauty Clinic A at 44.5 means 35–45% of consultation-stage prospects are lost to price comparison against Scale Operators. At lead volume of 80–120/month and ticket Rp 4–6M, that’s Rp 90–200M per month in recoverable revenue from moving the trust score to 62 — where JAC sits.
This isn’t opinion. It’s multiplicative math that Maister established for the consulting profession thirty years ago, applied to traceable data.
Third lens — an unbalanced CDJ funnel
The most surprising part of Beauty Clinic A’s audit is the funnel split.
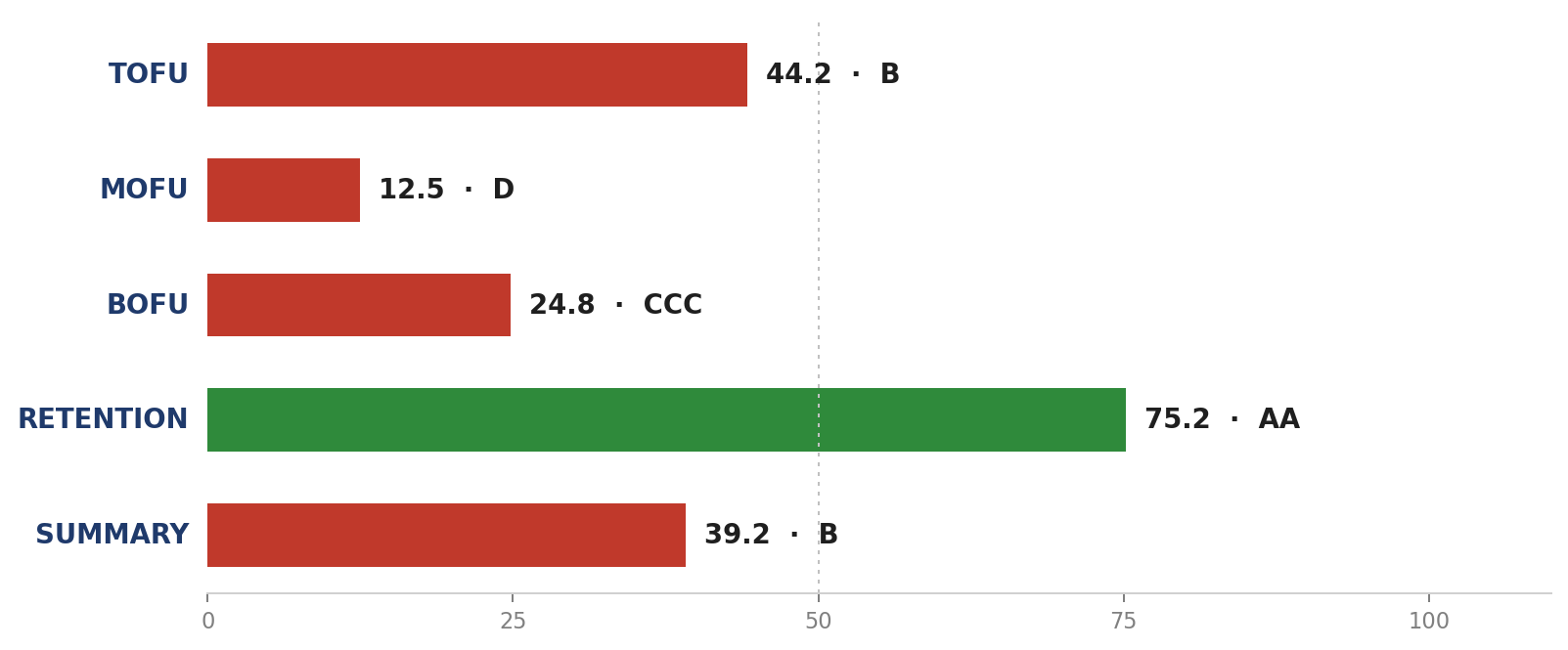 Exhibit 3 — four CDJ stages for Beauty Clinic A (engine v2). The threshold 50 (dashed line) separates defensible bands from indefensible. MOFU 13.1 is the most expensive finding in this audit; Retention 69.6 is the pillar most agencies fail to cite.
Exhibit 3 — four CDJ stages for Beauty Clinic A (engine v2). The threshold 50 (dashed line) separates defensible bands from indefensible. MOFU 13.1 is the most expensive finding in this audit; Retention 69.6 is the pillar most agencies fail to cite.
- TOFU 46.4 (band BB) — awareness is adequate. People know Beauty Clinic A exists.
- MOFU 13.1 (band D) — biggest leak. Prospects who already know don’t have the content infrastructure to support a booking decision. (I1 Why-us page = 0; I2 Comparison-stage blog = 0 — these two zeros drag the MOFU score into band D.)
- BOFU 24.2 (band CCC) — conversion stage broken. WhatsApp autoresponder missing, before/after on the blog instead of service pages, no-claim graphics on paid IG.
- Retention 69.6 (band A) — patients who came back are loyal. Still the strongest pillar of the four funnel stages.
The strategic consequence: the next 30 days’ focus is NOT fixing all four stages evenly. Retention is already winning; every rupiah going into a retention program in month one is a misallocated rupiah. MOFU and BOFU are the priority. Detailed plays in the IPM.
You don’t have a growth problem. You have a recognition problem. Prospects exit your funnel at MOFU because they can’t differentiate you from three other clinics that look identical in Google search.
Layer 3 — from scores to prescription
Output of Layer 2 is scores. Output of Layer 3 is decisions. Layer 3 has two sub-layers that have to be distinguished: (a) deterministic engine output (32 calibrated ERRC buckets), and (b) Investment Priority Matrix authored by a judgment layer on top (13 plays, prescriptive).
3a — Engine output: 32 calibrated ERRC buckets
Engine v2 produced 32 ERRC buckets for Beauty Clinic A as Stuck-in-Middle. Distribution: 31 ELIMINATE + 1 REDUCE + 0 RAISE + 0 CREATE.
Why almost all ELIMINATE? That’s the Stuck-in-Middle posture. The calibration multiplier table we shipped in engine v2 (2026-04-27) maps each archetype to a strategic direction: Stuck-in-Middle with multiplier m_E=1.3 means “clarify first, eliminate confusing signals.” Multiplier m_C=0.6 means “don’t expand/CREATE while posture is unclear.” An ELIMINATE-dominant engine output is the correct calibration for that posture — not calibration debt.
Historical note: the older engine v1 used a flat 0.6× across all four actions → 22-all-ELIMINATE output that wasn’t prescriptive. That was the documented v1 calibration debt, and engine v2 (2026-04-27) replaced it with the per-archetype × per-action table. What you see now (32 distributed buckets) is v2 output, not v1.
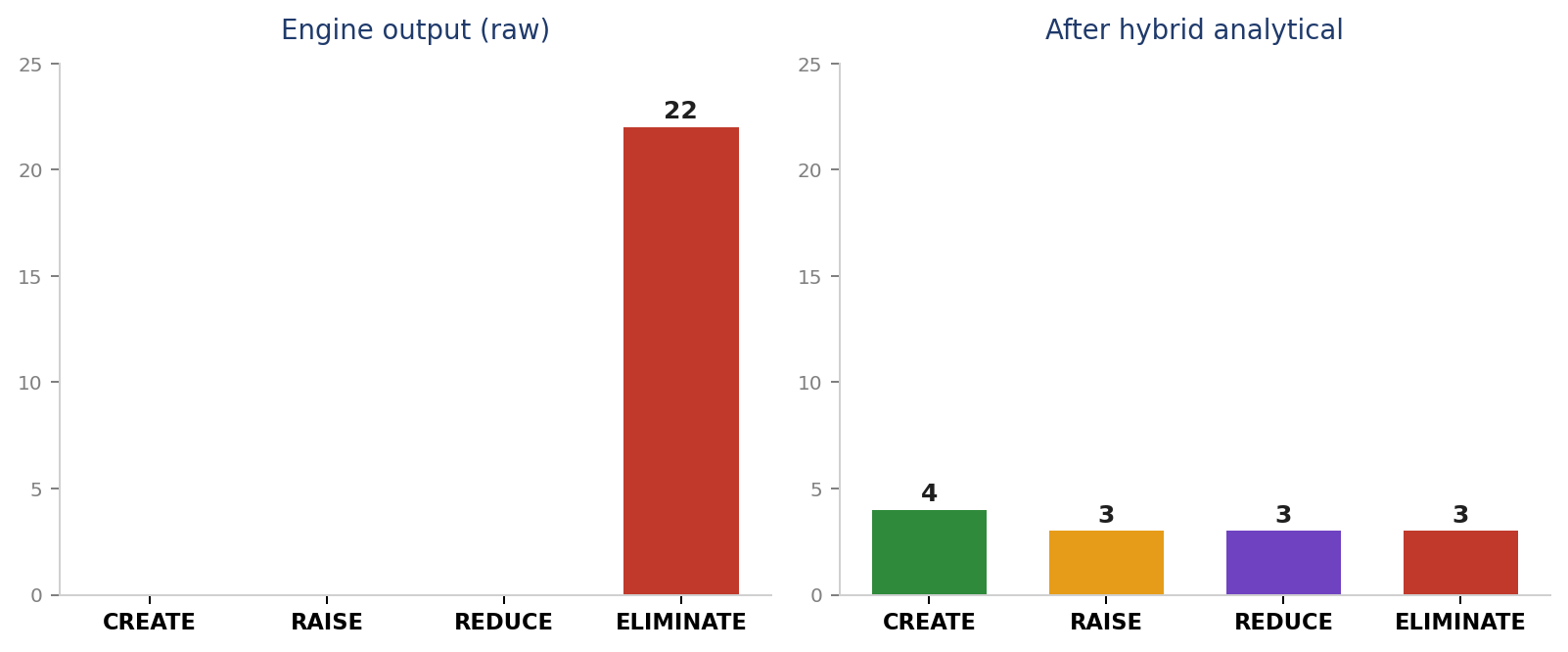 Exhibit 4 — Left: 22 raw buckets from old engine v1 (all ELIMINATE — calibration debt). Right: 32 calibrated buckets from engine v2 (31 E + 1 Rd + 0 R + 0 C). Engine v2 calibrates by archetype but stays ELIMINATE-dominant for Stuck-in-Middle posture.
Exhibit 4 — Left: 22 raw buckets from old engine v1 (all ELIMINATE — calibration debt). Right: 32 calibrated buckets from engine v2 (31 E + 1 Rd + 0 R + 0 C). Engine v2 calibrates by archetype but stays ELIMINATE-dominant for Stuck-in-Middle posture.
3b — Investment Priority Matrix: 13 plays (Claude judgment layer on top of engine)
Engine output is a “what to clarify/eliminate” backlog. IPM output is a “what to build over the next 30 days” decision. Two different things — IPM is authored by a Claude judgment layer above the engine, not by the engine itself.
The judgment layer reads the 32 ERRC buckets + archetype + funnel diagnostic + financial context, then reframes the direction from ELIMINATE-backward to CREATE/RAISE-forward: “ELIMINATE comparison-page absence” becomes “CREATE comparison-stage blog content.” Each reframe applies two explicit criteria: “is this data point a buildable capability?” → CREATE/RAISE; “is this competition already lost?” → REDUCE/ELIMINATE.
Final output: an Investment Priority Matrix of 13 plays mapped to 30 days, total investment Rp 22M, estimated return Rp 104–175M per month, payback at Week 3.
Every play in that matrix points to one Process Map data point that’s currently scoring 0 or very low. No play appears because of “best practice” — every play appears because there’s a cell in the xlsx producing an indefensible score.
A few examples:
- CREATE WhatsApp autoresponder with 4 keyword triggers → addresses G1 (WA pre-filled message = 0) and G3 (WA auto-reply = 0). Investment Rp 2M. Estimated return Rp 24–38M/month.
- CREATE Bridal Skin Program landing page → addresses I1 (Why-us page = 0). Margin 78%, only 2 direct peers in Jakarta. Investment Rp 4M. Estimated return Rp 18–30M/month.
- RAISE before/after gallery from blog to service pages → addresses E19 (Before/after gallery exists = 0). Investment Rp 0.5M. Estimated return Rp 12–18M/month.
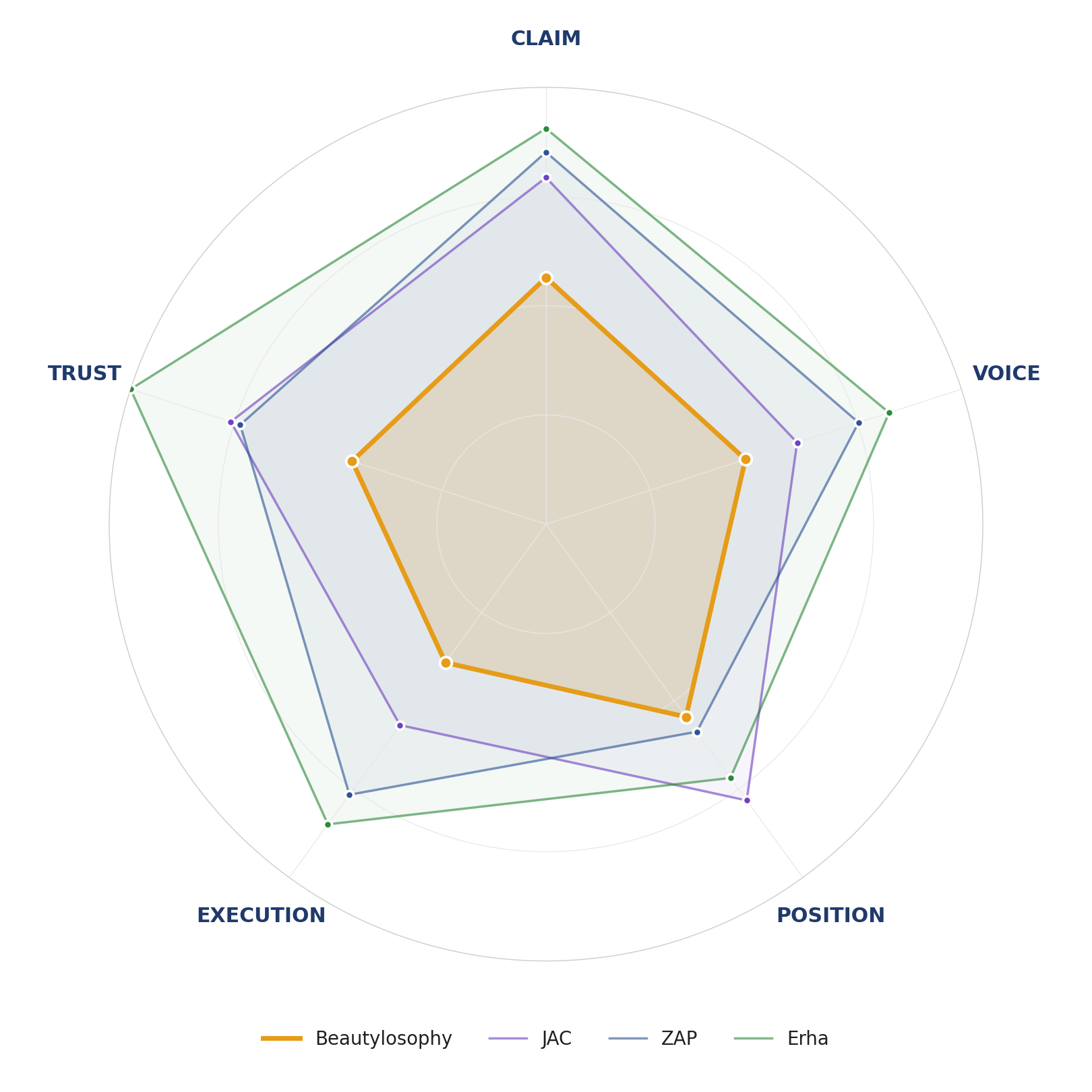 Exhibit 5 — Beauty Clinic A’s Five-Lens radial: CLAIM, VOICE, POSITION, EXECUTION, TRUST. Red polygon = Beauty Clinic A; gray polygon = mean of three peers (ZAP, JAC, Erha). Cells where red sits outside gray are DOMINATE cells; cells where red sits inside are CONTEST or CEDE.
Exhibit 5 — Beauty Clinic A’s Five-Lens radial: CLAIM, VOICE, POSITION, EXECUTION, TRUST. Red polygon = Beauty Clinic A; gray polygon = mean of three peers (ZAP, JAC, Erha). Cells where red sits outside gray are DOMINATE cells; cells where red sits inside are CONTEST or CEDE.
What Beauty Clinic A walks away with
The client leaves the engagement with four artifacts:
- A 30+ page report (v4 release) with 5 data exhibits, all 5 ANYÉ Lens diagnostics (POSITION + VOICE + CLAIM + EXECUTION + TRUST), and the full 13-play IPM walkthrough. 9 chapters: how-the-audit-is-produced, Layer 1 evidence collection, 5 lens chapters, ERRC + IPM, 30-day plan. The PDF you can download below is the v4 version (released 2026-04-27).
- A live workpaper xlsx — 7 sheets, formula-driven where math allows. Raw_Inputs (61 data points) → Group_Rollups → Lens_Diagnostic recompute via Excel formulas when any cell changes. Engine_Outputs sheet documents what came from engine v2 functions vs Claude judgment layer. Methodology_Trace sheet provides audit-trail completeness check.
- A walkthrough deck for internal team meetings — 22 slides telling the audit in ~30 minutes.
- A 30-day plan with each play mapped to its Process Map ID, cost, and estimated return.
All of these artifacts persist: when ANYÉ runs a re-audit at 60 days, the new output can be compared row-by-row with this output. No work starts from zero.
What this could mean for you
If you own a Jakarta clinic with revenue Rp 200–800M/month and curiosity about where your marketing rupiah should actually flow:
- Download the full report below and compare it to your own clinic.
- Compare your data-point table to Beauty Clinic A’s. The patterns you see there tend to surface in your clinic too.
- Reach us via WhatsApp for a 30-minute conversation about whether the Pro Competitive Intelligence audit makes sense for your specific situation.
Methodology note — what’s still GAP
This audit is written with what we call “GAP-honest” discipline — every data point with an unverified source is flagged explicitly. For Beauty Clinic A, 4 of the 61 data points are GAP:
- G2 (WA response time tested) + G4 (phone answered) — both require a manual phone test scheduled for the audit follow-up. In the meantime, the R component of Maister Trust (Reliability) is over-weighted to two measured inputs (E21 + F14) — that’s why R=100 in this engine output but is expected to drop to 65-75 once GAPs are filled.
- H18 (TikTok presence) + H20 (TikTok engagement) — the TikTok scraper pipeline (WF-01C) is planned but not built. The audit follow-up in 6 weeks will fill both.
Note on report version: v3 (released 2026-04-26) had 16 pages, 4 chapters, 2 of 5 ANYÉ Lenses. v4 (released 2026-04-27, English-first) is the current canonical version — 30+ pages, 9 chapters, all 5 ANYÉ Lenses, full IPM walkthrough. Bahasa transcreation of v4 is in progress; until then, the Bahasa case-study reader can download v3 (16-page Bahasa baseline) or read the v4 English edition.
These GAPs do NOT change the headline findings (Stuck-in-Middle, MOFU catastrophic, Retention as undervalued strength, ERRC ELIMINATE-dominant calibrated). They’re flagged explicitly so readers know where this audit ends and the next iteration continues.
A note on publication
We publish this case study with Beauty Clinic A’s consent as part of our commitment to published methodology. Three identifying data points (exact location, owner contact, one operational data point) are redacted for client safety. All scores, all plays, all return numbers are real — derived from engine v2 (released 2026-04-27).
We do this because ANYÉ’s central thesis is: published methodology beats hidden methodology. The audit you see here isn’t a secret. It’s how we work, placed in public so you can judge whether the approach fits your business before paying us a single rupiah.
Download
- Full audit report (PDF, v4 — 30+ pages, 9 chapters, 5 lenses, full IPM walkthrough)
- Live audit workpaper (Excel — 9 sheets, formula-driven, full traceability) — open in Excel; Raw_Inputs has
source_path+evidence_quote+captured_atcolumns so every score traces back to its underlying raw evidence. Sources_Manifest sheet lists all 12 input flows with disk paths + last-refreshed timestamps. Trace_Spot_Check sheet walks 5 representative data points end-to-end through every layer. - v3 baseline (Bahasa, 16 pages, 4 chapters): v3 PDF — kept as historical reference; superseded by v4 EN
The workpaper xlsx is the living spine of the audit. The PDF is a snapshot of workpaper + engine state on 2026-04-27.
Frameworks referenced
- Investment Priority Matrix — IPM output explained in Layer 3.
- Process Map — the 202-data-point schema Layer 1 fills.
- Rating Engine — five deterministic functions producing Layer 2.
- Five Lenses — CLAIM/VOICE/POSITION/EXECUTION/TRUST visualized in Exhibit 5.
- H-W6 Authority Gate — citation discipline that makes this article defensible.
Read the case study in Bahasa →
Published 2026-04-26 by ANYÉ Digital · Audit version referenced: v3 (engine v2 re-run 2026-04-27) · Audit date: April 2026